服务热线02152235399
烈冰NovelBrain®云平台自上线以来,接受了众多科研团队的全方位、多层次的平台功能和安全测试,同时也在烈冰内部的真实工作环境中不断经受考验,期间经过两次慎重的系统更新,平台成功从V1.0升级到V3.0,在网络图绘制、弹性结果报告和人重分析加速等各方面给用户带来惊喜体验。同时,我们也在更严苛的压力测试中不断对系统进行改进,做懂科研的生信云平台。

为进一步提升平台的用户体验,打造行业一流的生信自动化大数据分析系统,烈冰隆重推出NovelBrain®云平台的全新升级版本V4.0,升级内容包括分析工具更新和pipeline优化、系统底层架构的优化、组学研究的全面加速、生物数据的压缩存储以及数据库的完备和管理升级,全方位保证您的数据安全和分析效率,助力您的科学研究。
1、分析工具丰富和pipeline优化
NovelBrain云计算系统可以帮助快速准确地进行各组学分析,包括人类重测序、基因组测序、全转录组测序、miRNA测序、表观遗传测序、微生物测序等几乎全部二代测序类型。事实上如果出现新的测序技术或工具,烈冰会第一时间将其添加至NovelBrain平台,进行分析测试并用于实际生产。
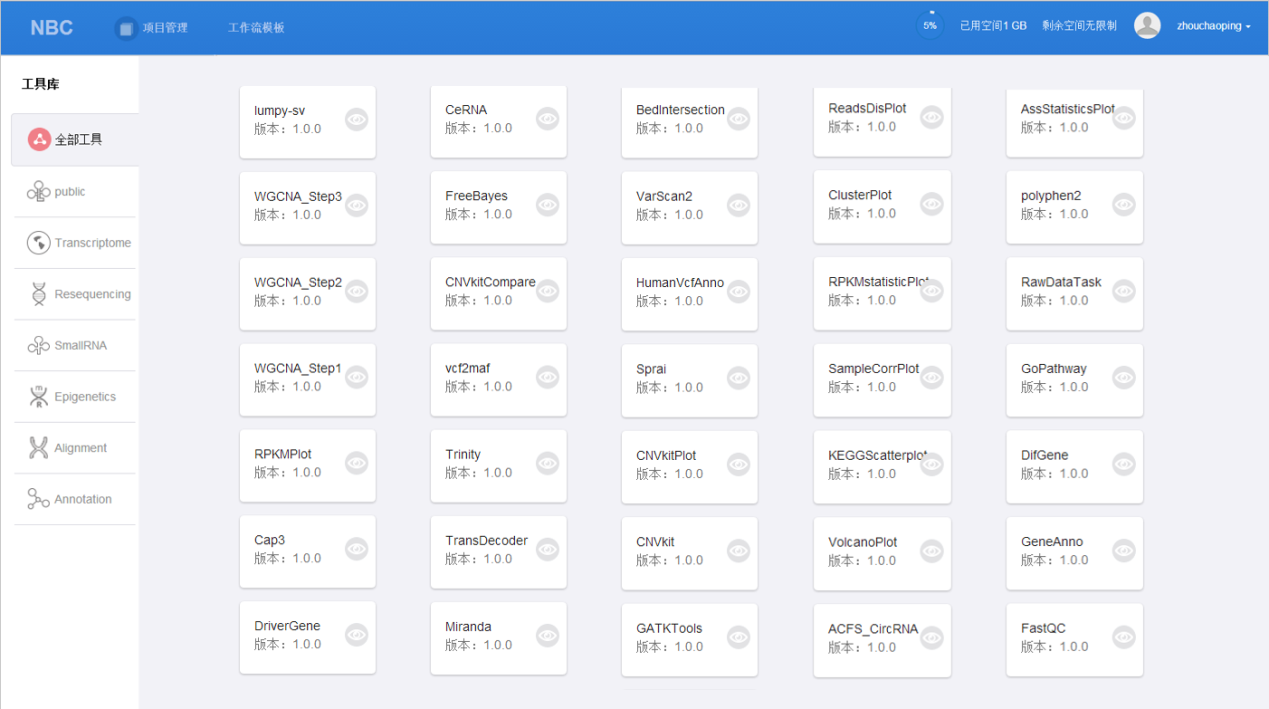
丰富的分析工具和标准流程化的pipeline是进行数据分析的“物质基础”,NovelBrain V4.0对新开发的分析工具进行了整合,并进一步优化了多组学分析流程:
(1)分析工具全新整合
NovelBrain在作为烈冰生产系统的过程中,不断地上线并积累各类数据分析工具,截止V4.0版本已包含400多个分析工具,其中很多分析工具譬如RnaSeqMap,一个工具就包含了hisat2、star、mapsplice、tophat这4个分析软件。因此实际整合软件数量1000+,不仅包含二代测序分析软件,还覆盖GWAS相关、motif预测、基因注释等多个生物信息领域。
NovelBrain本次升级新增了Diamond、fq2fa、fa2fq、seqSample、seq2tab、multiBamSummary、gff2tab、sedBy2List、tsv2csv、csv2tsv、SpeciesIndex_miRNA、sRNADetect、sRNATarget、cuffqaunt_cuffnorm、map_stat等新开发的分析工具,极大地拓展了数据分析的可能性,满足不同需求层次生信分析人员的要求,高效实现自助式数据分析,轻松探索发现数据意义。
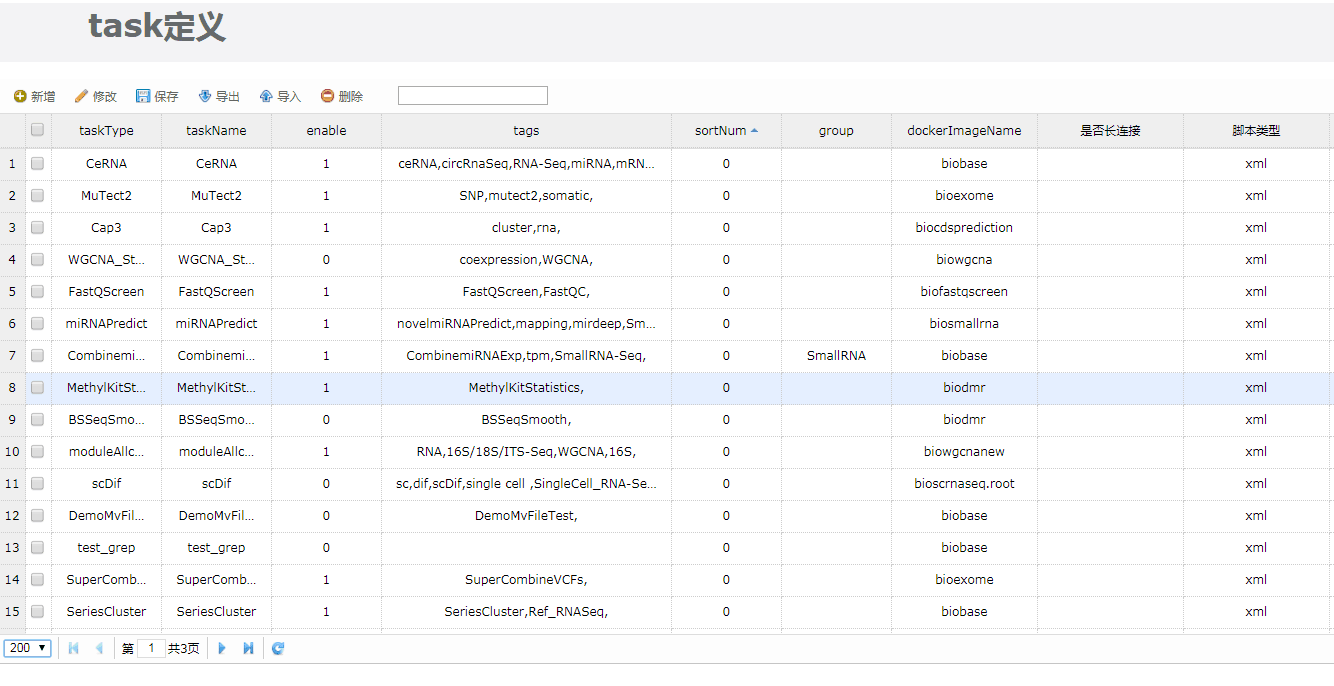
随着生物信息的发展,烈冰也在不断向系统添加更多的工具。而已上线的工具,在使用过程中也对某些参数的使用场景理解更为深刻,从而不断得到优化。
(2)pipeline优化
丰富的工具只是保证数据分析可进行的第一步,想要漂亮的分析数据,还需要完善pipeline支持。譬如DnaSeqMap、FastqFilter这两个工具,其在人类重测序分析和在miRNA分析中的参数设置都是不一样的,因此NovelBrain V4.0不仅对不同Pipeline中工具的参数都针对性地进行了优化,对不同的分析流程还加入了经过实际生产甚至实验验证的调优。
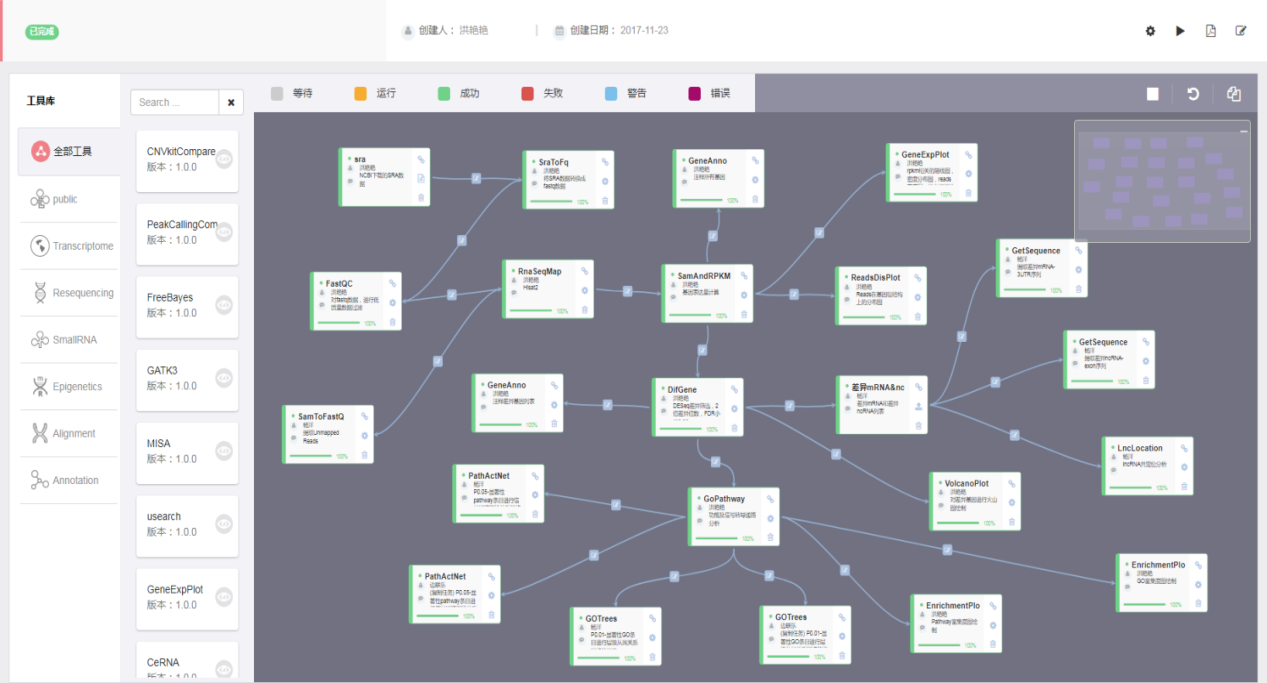
例如在有参转录组分析的pipeline中添加了lncRNA检测和分析,从而获得更丰富的转录组数据,便于后续的联合分析,对数据进行深度挖掘:

LncRNA的基因富集分析和靶向分析
Liu et al., Nat Commun, 2016/ Miao X et al., Sci Rep, 2016
同时,NovelBrain V4.0还在无参转录组pipeline中添加了基因预测和序列分步聚类,使各样品中表达丰度较低的转录本组装得更完整,准确发现潜在的功能基因,为下一步研究提供方向。
另外,V4.0针对性地对人类全基因组/外显子组 pipeline中的GATK-Best-Practice部分工具参数进行了调整,增加了FreeBayes对最后结果的校正,使流程化分析更智能,全方位保证数据质量。
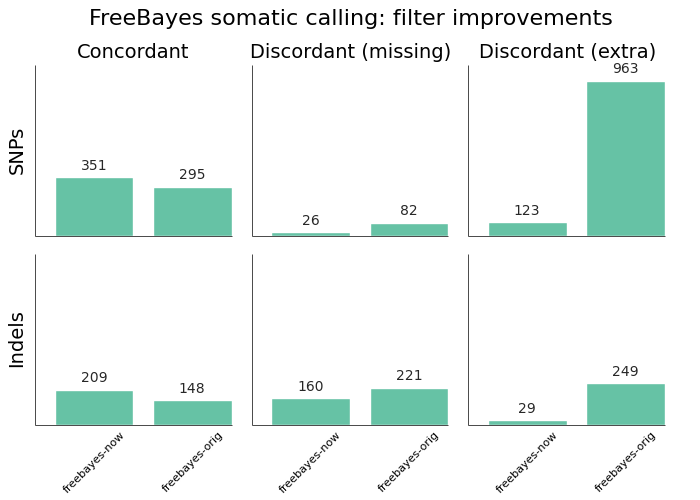
图片来源:GitHub
(https://github.com/chapmanb/bcbb/blob/master/posts/cancer_validation.org)
2、系统底层架构优化
云计算系统是一个复杂的分布式系统,新上线的系统在设计编码之初很难完整地覆盖到各种异常场景。因此在长时间高负载运行时,总是会出现各种各样的异常错误,从而影响数据的安全和分析结果的准确度。
NovelBrain云计算系统一方面在编码上有严格的规范,要求测试代码的覆盖度超过70%,同时烈冰也从2013年起,就将NovelBrain作为自己的生产系统实际用于二代测序数据的分析,目前日均分析500GB,峰值数TB以上的测序数据,系统自然地处于长期的压力环境下,很多问题会及时暴露并得到修正。
在长期的生产环境压力运行状态下,我们解决和优化了大量的问题,如:
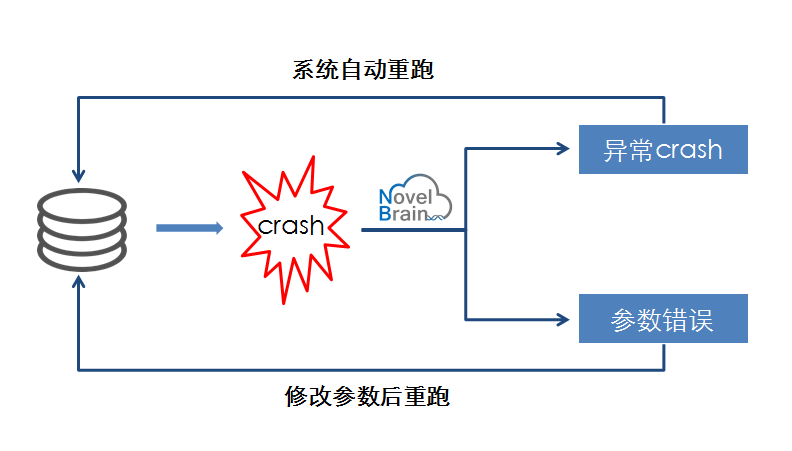
(1)任务异常crash自动重跑
很多工具在运行时会异常crash,包括jvm虚拟机崩溃、系统异常崩溃、机器宕机等多种情况,这些情况不仅会导致数据丢失,对数据安全造成威胁,同时还需要人工检查crash的原因,增加运行成本。针对这种情况,NovelBrain技术团队在 V4.0版本新增运行任务实时监控功能,如果侦测到异常crash,则会将任务重新投递并运行,节省时间和人力。同时,对于因参数设置原因导致的任务出错,系统会将其与异常crash有效区分,记录至数据库并供生信工程师查阅,及时发现错误并纠正。
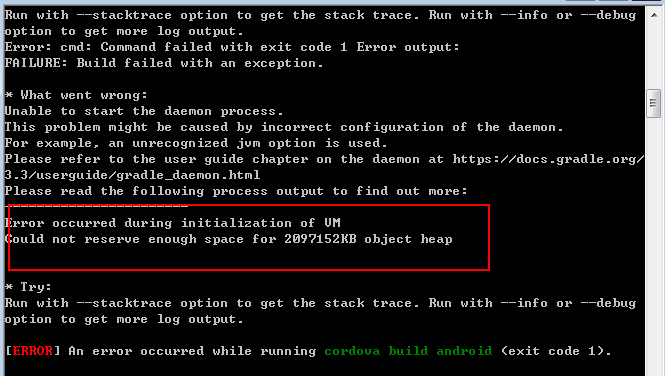
(2)运行内存超出预设引起的crash
部分工具在运行时,请求的内存大小会超过虚拟机预设的内存。根据一般的linux机制,系统会将这种超出内存使用范围的进程杀死,而这会引起结果异常并很难判断哪个步骤出现问题,因此在NovelBrain V4.0中我们关闭了这个设定,并重新配置了虚拟机,不允许进程使用超过虚拟机设置的内存,从而避免进程被杀死。
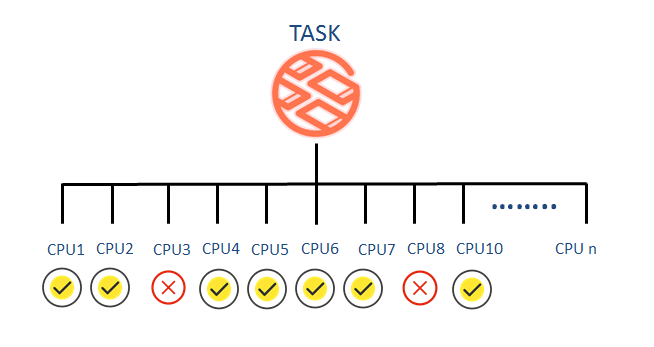
(3)Hadoop-Yarn容器数量计数问题
一般一个任务投递时会启动多个容器并行计算,而Hadoop-Yarn无法保证每个容器能顺利跑上,同时由于反馈机制的缺失,任务投递者只有在项目运行结束后,才知道某些样本并没有得到处理,从而浪费了很多时间来进行“扫尾”。NovelBrain V4.0中,系统可自行定义计数器来对成功运行的容器进行计数,实时显示成功运行的样本个数,保证不会漏掉分析样本。
(4)任务监控修正
实时监控分析任务的cpu/内存使用是一个非常重要的内容。分析任务的时长从数分钟到数天不等,因此监控的时间间隔则很有考究,频率过低则无法有效监控到短时间任务的信息,频率过高则长时间任务会获取太多无意义的信息,白白浪费数据库空间。NovelBrain V4.0采用了幂次降低策略,随着时间增加,降低采样频率。同时还配合拐点采样策略,即如果监控到cpu/内存的异常变化,则会将该时间点的信息存入数据库。在保证数据量合适的同时,也不会漏掉异常点。
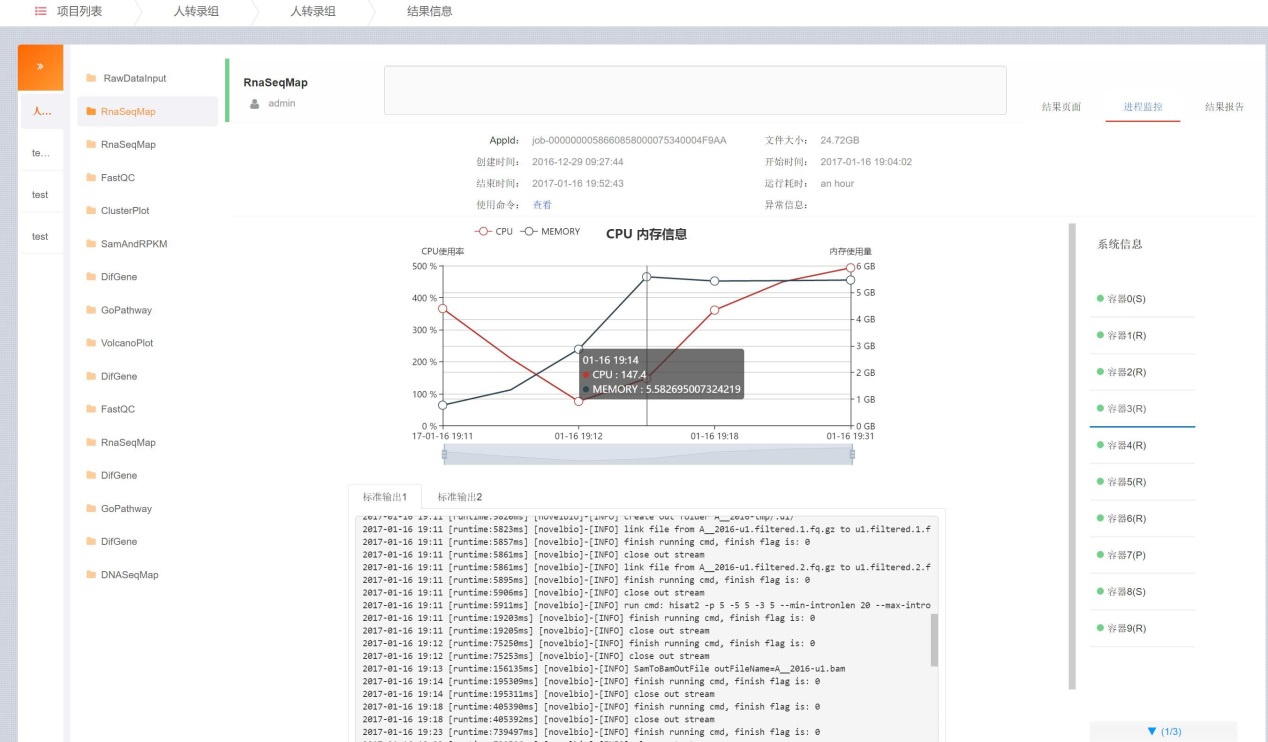
以上列举了部分在长时间的高负载生产环境中出现的问题,以及NovelBrain V4.0的修正策略。正是这些持续不断的修正,才是NovelBrain可以真正应用于生产,可以稳定运行的关键保证。
3、全组学研究分布式加速
NovelBrain是一个天然的分布式系统,在NovelBrain上投递的task/pipeline,总是会自动分配到多台低负载的机器上进行并行计算,大幅度缩短数据分析的时间。同时系统还可以设定某个工具的总并发数,保证多个大型项目同时在集群上分析时,不会互相抢资源。如一个100台服务器的集群,两个用户均投递了300个样本的基因组分析,那么每个用户可以将并发数限制为40,这样双方不会互相抢占资源,系统甚至还可以预留足够资源用于其他用户的分析。
之前的V3.0版本NovelBrain针对性地对人类重测序进行了优化和加速,4小时即可完成单样本的分析,打破了人重分析的瓶颈。V4.0更是将该该技术应用于所有组学研究,实现全组学的测序分析加速,有效提升数据分析效率。
此外,对于并行计算的任务,NovelBrain也有完善的监控系统对每一个容器的cpu内存进行监控,同时将运行的命令和日志自动存档,方便未来给第三方机构重现结果。
4、数据压缩存储
随着二代测序数据量的上升,数据压缩刻不容缓。以公有云为例,传统压缩和计算的费用比约为7:1-8:1,也就是说每1万的计算费用需要7-8万的数据存储费用。目前对于数据压缩有很多方法,如对fastq进行压缩,使用磁带机或公有云进行冷备等。NovelBrain认为数据压缩存储是一个系统化工程,需要多个方案协同配合才能获得最佳的存储效果。
因此NovelBrain V4.0提出了数据压缩存储的一体化解决方案,包含以下四个方面:
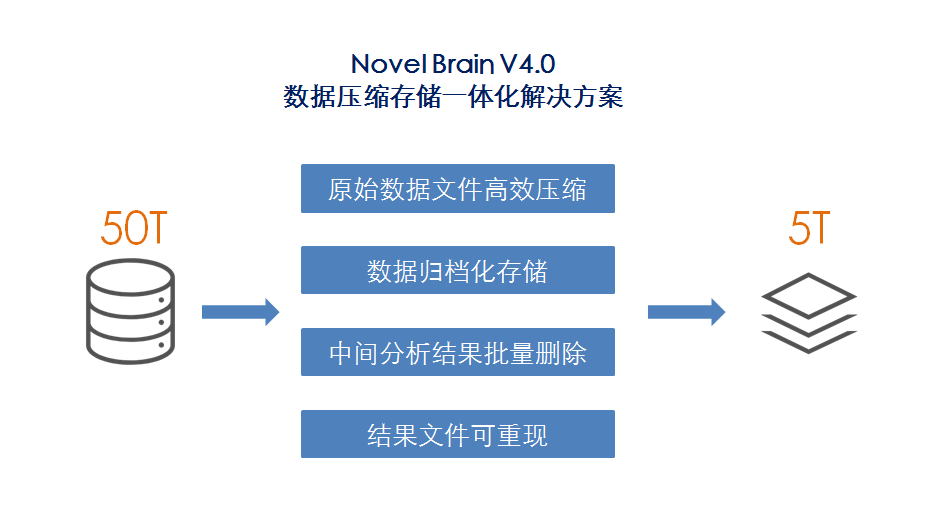
(1)原始数据fastq文件的高效压缩
数据上传完毕后,NovelBrain V4.0即自动使用开源软件对fastq文件进行压缩,可以获得比fastq.gz小非常多的无损原始数据,分析时自动解压缩并进行分析。
(2)数据归档化存储
NovelBrain V4.0在数据分析完毕之后,即可自动对原始数据进行归档存储,大幅度降低存储的费用。
(3)中间分析结果批量删除
二代测序分析过程中会产生大量的中间结果,如GATK-Best-Practice会产生Realign,Remove PCR duplicate等多个bam文件,这些中间结果非常占存储空间。NovelBrain V4.0中的所有分析结果都在数据库中存档,因此可以细粒度的进行中间结果的删除。
(4)结果文件可重现
经常会有客户或reviewer询问或查询中间结果,因此只有结果文件可重现,我们才能放心的删除中间结果。NovelBrain V4.0对线上的工具做了一些调整,包括工具参数的增减或修改,软件版本的更新,和运行脚本的调整等,对分析工具进行版本控制,保证分析结果可重现。
结合以上多个步骤,NovelBrain可以大幅度降低数据存储的成本,真正做到数据存储的高效和成本控制。
5、完备数据库和可扩展的物种管理
对于分析使用到多个物种的大型实验室和公司,在做比对或注释分析时总是个麻烦事情,一方面需要对不同物种、不同版本的索引进行管理,另一方面在分析时还需要指定冗长的物种文件夹路径。
早在2013年,NovelBrain就开始使用数据库来记录物种版本、Annotation、GO、Pathway等信息,在数据库管理方面经验丰富;2014年,NovelBrain即开发了完备的物种管理系统,并对其不断优化;2016年开发了新版的物种管理系统。当前的NovelBrainV4.0更是对物种管理系统进行了全面升级,包括自定义的索引工具,可以自由上线包括bwa、bowtie在内的多种对染色体建索引的工具,也支持一键对新上传的物种建索引。同时V4.0也支持上传自定义的miRNA文件、GO/Pathway、Blast文件等,方便用户导入自己的注释信息。在数据分析时,分析工程师仅需要简单选择物种、版本、数据库这三项,系统会自动将数据库中的索引路径、注释信息等对接到分析工具中,快速简单的进行数据分析。
经过此次升级,NovelBrain®云平台V4.0成为业内更懂用户、更适合科研、更便捷、更高效的生物医疗云平台之一,实现了NovelBrain的里程碑式飞跃。本次V4.0版本升级,会第一时间更新到老用户的平台上,欢迎各位老师进行压力测试,并向我们提出宝贵的意见和建议。烈冰安全稳定可靠的运维体系,为NovelBrain的热爱者保驾护航,让每一个普通人都可以自己分析自己的数据,轻松了解自己数据的价值,并赋予数据生物学意义。
烈冰于2010年成立至今,身经百战,数百篇文献支持。9年间历经海量数据检验,已为600+国内外机构服务5000+项目,业务领域覆盖科研机构,大型药厂,医院,检验机构等。从烈冰助力首篇circRNA研究文章(Sci Rep. 2016 Mar 2;6:22572.)到人类血液外泌体长链RNA数据库exoRBase(![]() www.exoRBase.org),从基于Ion Proton测序仪的第一篇转录组文献(BMC Med Genomics. 2014 Aug 9;7:49)到第一篇高分转录组文献(Nature. 2016 Feb 4;530(7588):98-102),NovelBrain
www.exoRBase.org),从基于Ion Proton测序仪的第一篇转录组文献(BMC Med Genomics. 2014 Aug 9;7:49)到第一篇高分转录组文献(Nature. 2016 Feb 4;530(7588):98-102),NovelBrain![]() 云计算平台身经百战,不惧考验,献身科研!
云计算平台身经百战,不惧考验,献身科研!
